
从比并 JSON 库谈开源意义
在开发 RapidJSON 期间,我建立了另一开源项目 nativejson-benchmark,至今已整合 41 个 C/C++ JSON 开源库,评测它们对标准符合程度以及性能。本文先谈一下评测结果,再谈这个项目的意义。
评测方法
标准符合程度(conformance):
- 使用 JSON_checker 判断是否能分辨正确及错误的 JSON(parse validation)。
- 解析字符串类型 JSON,如正确结果比对(parse string)。
- 解析数字类型 JSON,如正确结果比对(parse double)。
- 生成 DOM,再用 DOM 生成 JSON。判断来回往返(roundtrip)的字符串是否相同。
有些库可能没有生成 JSON 的功能,那么就不能完成来回往返检测。
性能检测:
- 解析 JSON 至 DOM(parse)。
- 把 DOM 转换至 JSON(stringify)。
- 美化转换(prettify)。
- 遍历 DOM 统计各种 JSON 类型的数量及字符串长度(statistics)。
- 使用 SAX 做来回往返(sax roundtrip)。
- 使用 SAX 做统计 (sax statistics)。
- 生成一个程序,检测可执行档的大小。该程序能解析 JSON 至 DOM 并把统计结果打印出来。
现时有 3 个性能测试用的 JSON,合共大小是 4.6MB。
加入此评测的库,最低限度要能实现 parse 和 statistics。其他检测是可选的。
结果
以下是 2016 年 9 月 9 日,在 MacBook Pro (Retina, 15-inch, Mid 2015, Corei7-4980HQ 2.80GHz)、clang 7.0 64-bit 的执行结果。也可用互动版本观看。
综合标准符合程度(越高越好):
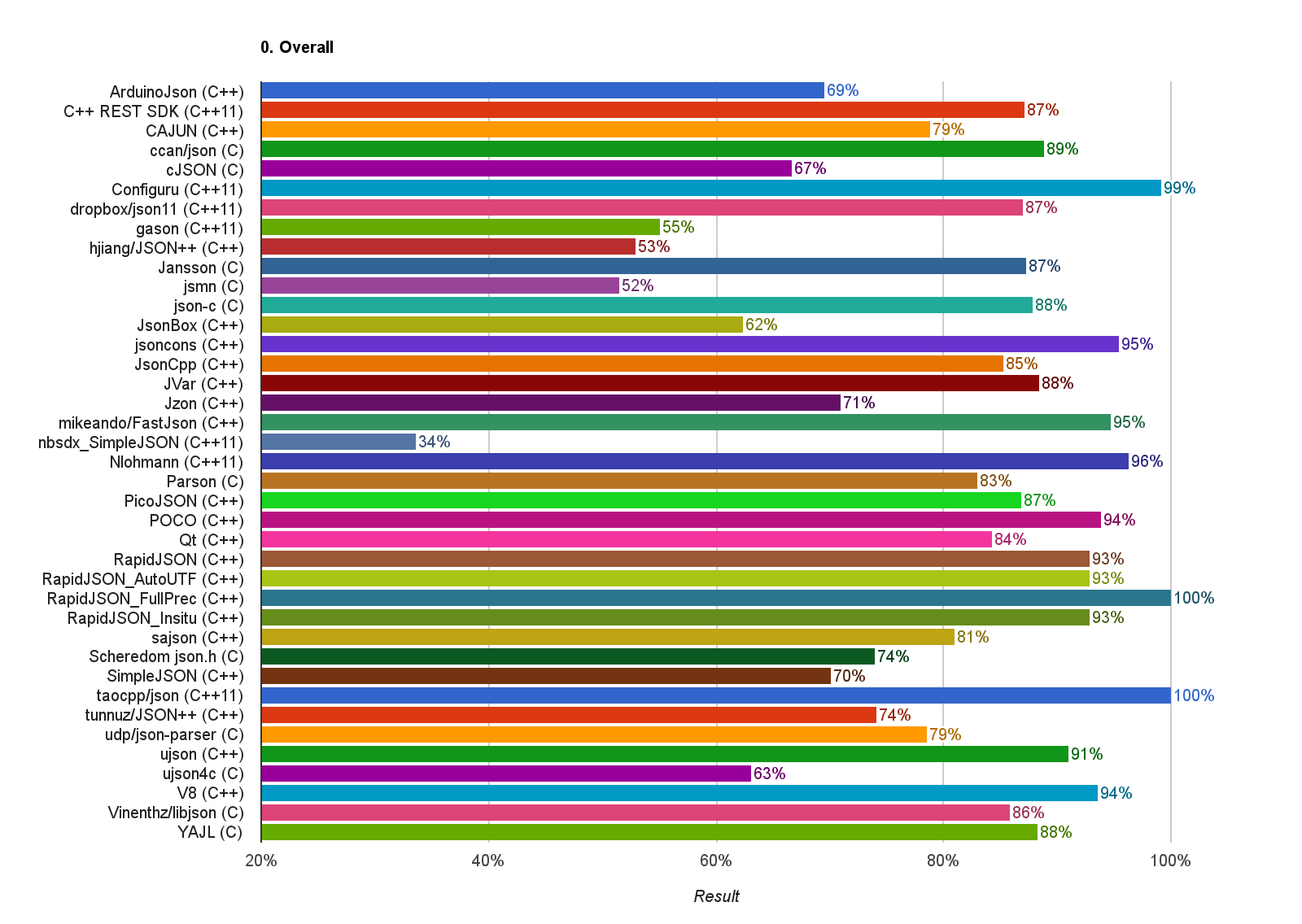
目前只有 RapidJSON 的全精度版本及 The Art of C++ / JSON (taocpp/json) 能获得 100% 完美得分。
其实这个检测中,部分数字解析及相关的来回往返测试是过于严格的,超越了标准所需的程度。有大约 80%-90% 已经可以说完全符合标准。之后会调整检测,把一些不属于标准必须的部分仅作参考,不算进整体分数。
有些库未能处理 ‘“\u0000”’ 和代理对(surrogate pair),尚可接受。有些库连 "\n" 这类转义符都不处理,就有点太过分了。
另一个常见问题是,一个 JSON 值结束后只能含有空白字符,例如[1, 2, 3] excited就是不合法的。有些库没做这个检测。
解析时间(越低越好):
.png)
前排是 RapidJSON、gason、ujson4c、sajson。然而,后三者的标准符合程度都较低。现时最快的 RapidJSON 以 7.9ms 解析 4.6MB 的 JSON 文本,比最后一名快 140 倍以上。
解析后的内存分配大小(越低越好):
.png)
Qt 未能成功检测其内存消耗,请忽略。RapidJSON 暂无对手,它在 x64 架构下的内存总消耗是 (JSON 节点数量 ✕ 16 字节 + 长字符串字节大小)。长字符串是指超过 13 个字节的字符串。之前发现了一个比 RapidJSON 更省的 jbson,但因为在 travis 上崩溃暂未加进评测。
Stringify 和 Prettify 时间(越低越好):
.png)
.png)
这两项都是 RapidJSON 完胜。这里有一个问题是测试的 JSON 数据中,最大的一个主要内容全为浮点数,而这类型的生成也是各类型中最耗时的,也许将来要再调整测试数据。
代码大小(越低越好):
.png)
由于要使用 V8 的 VM 来使用其 JSON 功能,所以执行文件特别大(静态链接)。较前排的 Folly、Qt、C++ REST SDK 都是使用动态链接的,所以特别小,其他的都是静态链接。而在静态链接库中,通常以 C 编写的较小,C++ 的较大。
起源
最初开发 RapidJSON 时,在项目内部写了一个性能测试,与 YAJL 和 JsonCpp 比较性能,仅量度耗时。然而,耗时并不是唯一需要量度的数值,也许一些库很快,却没有做各种处理,或是数字的转换方式并不精确。另外,要把各个其他 JSON 库加入 RapidJSON 的代码库中,也对使用者造成不便。
因此,后来就把那个性能测试独立成项目,制定了一个通用接口,每个库都只需实现该接口,便能作出各项检测,最后生成图表。
为了简化编译过程,整合大部分较简单的 JSON 库的时候,都是在测试 .cpp 中直接 #include 该库的 .cpp 实现。这样也确保编译参数都完全相同。只有像 Qt、V8、C++ Rest SDK 等需要自行安装。
学习
在整合这几十个库的同时,我也会参考他们的功能、API 设计、实现技术等等。遇到性能优良的库,也会仔细看看它有没有用到什么特别的技术。同时也会在想,有哪些功能都是缺乏的,了解更广,方能创新。
另一方面,我相信其他开发者也会通过这个平台,查看自己的库的优缺点,学习其他库并作出改进。当然,除了这种暗地里互相学习的,也有讨论交流的。
贡献
在建立这个项目以来,通常是被动地从 JSON 库的作者里接收 Pull Request,也许一些 JSON 库的作者也不知道有这个项目。
这个项目的目的,除了给予使用者一个参考,也希望能提升各个库的品质。没有一个库是完美的,需求各自不同。如果能提升品质,对它的使用者也有帮助。
因此,我最近为每个库的标准符合程度检测生成 markdown 格式的报告,并主动地发送成各个项目的 issue ,供他们参考。这个举动已获得不少回应,有些作者已积极修改一些问题。
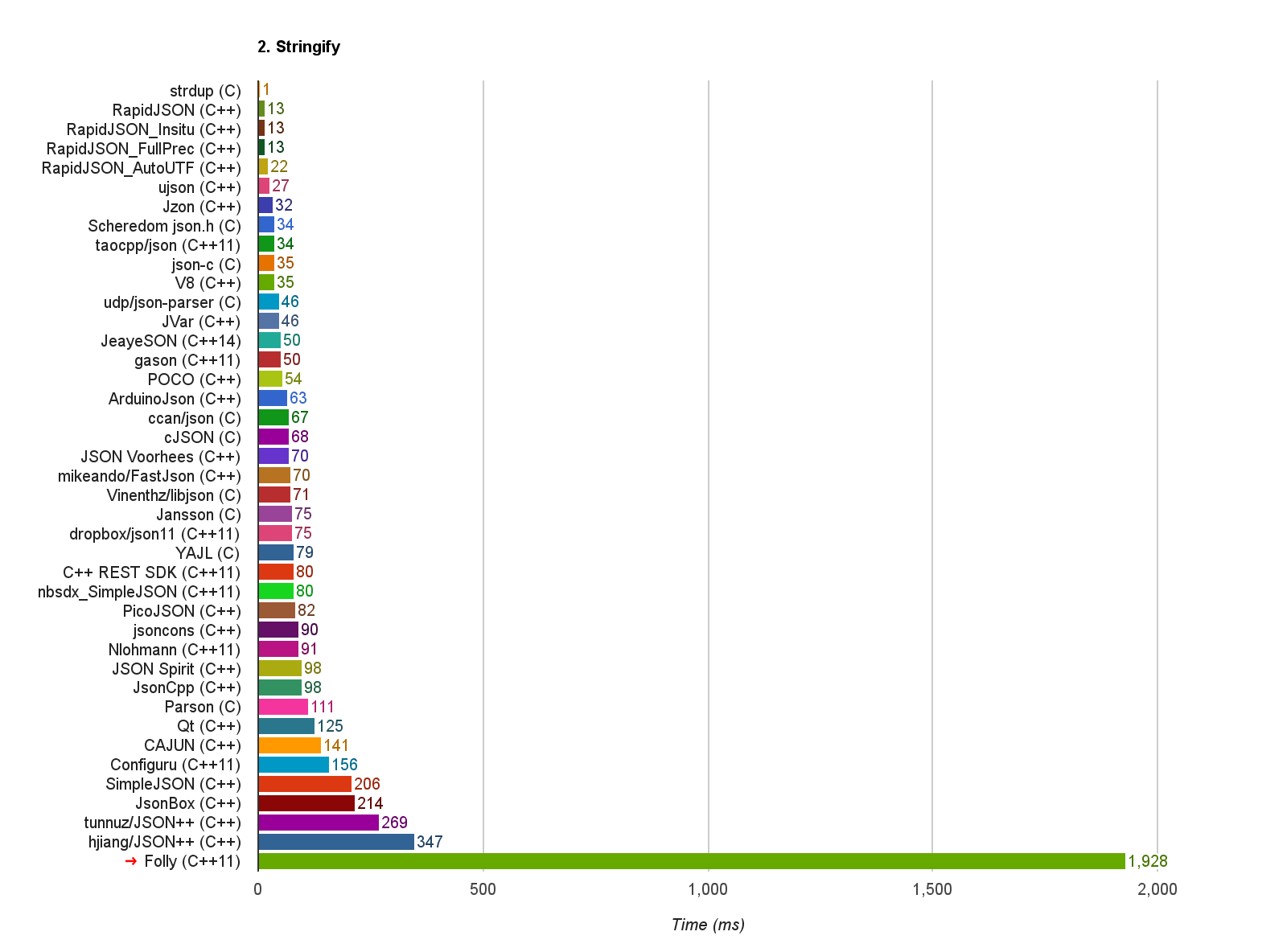
另外,我之前整合遇到一些问题时,也会发 issue 查询讨论。例如,最近一轮的排查中,发现 facebook/folly 的 toJson() 异常地慢:
经性能分析后,发现问题仅在于一行代码:
// json.cpp
void escapeString(
StringPiece input,
std::string& out,
const serialization_opts& opts) {
auto hexDigit = [] (int c) -> char {
return c < 10 ? c + '0' : c - 10 + 'a';
};
out.reserve(out.size() + input.size() + 2); // <-- 这一行
out.push_back('\"');
// ...
此行原来的意义,应该是希望预分配字符串的输出缓冲,避免过程中需要重新分配。但在一般的实现中,std::string::reserve() 在空间不足时,会把缓冲设置为指明的大小。由于每次的分配都是刚好够用而已,下次再输出字符串就必会再重新分配,造成 $O(n^2)$ 的性能瓶颈。而如果只是用 std::string::push_back(),它分配新空间会为现有大小的两倍(或其他倍数),达至分摊 $O(n)$ 的时间复杂度。所以,经过实验,只要删去该行,就能达到正常的性能:
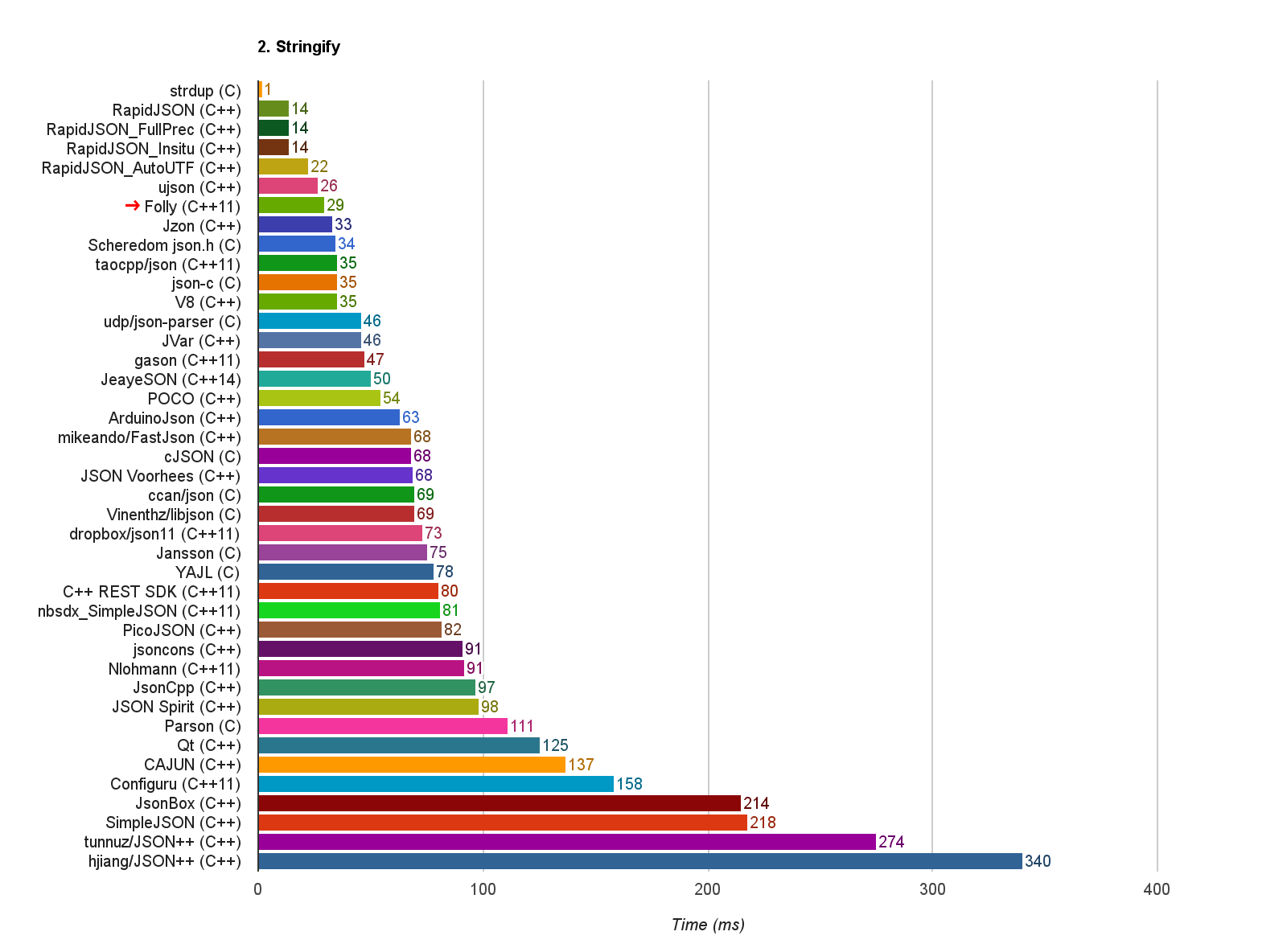
这个测试显示消耗时 1928ms ➔ 29ms,我已提供 issue 及 PR。
后语
JSON 的处理工作对于一些后台服务、嵌入式系统来说,可能是一个很重要的部分,影响整体性能。虽然现时我的工作其实并没怎么能用到这些功能,我仍然觉得,开发 RapidJSON 及这个评测项目对于我个人、公司及开源社区也是有帮助的。
我会持续更进这些项目。之前还希望加入其他原生库,例如是 Objective C、Go、Rust 写成的库,如果有熟悉这方面的同学,欢迎与我联系。
有鉴于看过这么多 JSON 库,最近也写了一个极简的 C JSON 库,希望用它来写几篇入门级的《从零开发一个 JSON 库》,供刚学过编程的大学同学阅读,请各位支持。
Milo Yip
RAPIDJSON