
估计 Grisu 算法以龙命名,是与上一代的 Dragon4 算法相关。
RapidJSON 代码剖析(四):优化 Grisu
我曾经在知乎的一个答案里谈及到 V8 引擎里实现了 Grisu 算法,我先引用该文的内容简单介绍 Grisu。然后,再谈及 RapidJSON 对它做了的几个底层优化。
Grisu是什么
Grisu 是把浮点数转换为字符串的算法。在 Chrome 里执行这段 JavaScript 实际上就调用了 Grisu:
document.write(1/3); // 0.3333333333333333
这个问题看似简单,实际上是很复杂的事情。
在1980年之前,许多 C 语言标准库中的 printf() 都会产生「不正确」的结果。Coonen 在那时候做了相关的博士研究[1],但并没有受到广泛的知悉和应用。1990年 Steele 等人发表了名为 Dragon4 的算法[2],通过使用大数运算来确保精确的转换。而这个算法应用在大部分 C 程序语言库的 printf(),以及其他用 printf() 来实现这功能的语言之中。
这样就20年过去,虽然中间有一些小改进[3][4],但基本的思路仍然是这样。到了2010年,Loitsch 发表了 Grisu 算法[5],而 V8 也实现了这个算法。
该篇文章阐述了3个算法,分别是原始的 Grisu,及其改进版 Grisu2 和 Grisu3。Grisu 算法比 Dragon4 等算法优越的地方就是一个字──快。以下简单介绍一下它们的特点。
首先,什么是「正确」的转换?其定义是,一个浮点数转换成的十进位字符串之后,该字符串可以完美的转换回去原来的浮点数,如果用C语言来描述的话:
// 除 +/-inf 及 NaN 外的浮点数都应该传回 true。
bool Verify(double d) {
assert(!isnan(d) && !isinf(d));
char buffer[32]; // 足够大么?
dtoa(buffer, d); // 双精度浮点数转换至字符串,是double-to-ascii
char* end;
double d2 = strtod(buffer, &end); // 字符串转换至双精度浮点数
return *end == '\0' && d == d2;
}
如前所述,Dragon4 使用大数运算,还涉及动态内存分配(你知道printf()里可能会做malloc()么?)。而 Grisu 则不需要,只需要用到64位整数运算便可以实现转换!所以那篇文章题目就以 “… with integers” 作结尾。
Grisu 的算法非常简单,但它有一个缺点,就是其结果并不像是给人看的。如文中的例子,Grisu 把 0.3 的打印成 29999999999999998e-17。这是「正确的」转换结果,它可以通过 Verify() 验证。
虽然该算法非常快,但一般人大概不会接受这样的结果。作者也因此研发出改进版本 Grisu2,在使用64位整数实现 double 的转换时,可以利用额外的 64 - 53 = 11 位去缩减转换的结果(53 为 double 的尾数位数)。Grisu2 可以把 >99.9% 的浮点数转换成最短的「正确」字符串,其馀<0.1%的浮点数仍然是「正确」的,但不是最短的答案。
也许一般人就见好就收了,毕竟已证明算法的正确性,只是有那么 <0.1% 情况未达至最完美的结果。不过该作者还是继续研究出 Grisu3。Grisu3 并不能解决那一小撮麻烦制造者,但它能在计算期间侦查到哪些 double 在这算法中未能得出最优的结果。既然办事快捷的小部门搞不定,就可以把它交给 Dragon4 或其他较慢的算法。
V8 里实现了 Grisu3 以及大整数的算法(我不肯定是Dragon4还是其他),后来Google也把它分离成为一个独立的C++程序库double-conversion。
为了优化 RapidJSON 的浮点数转换,也由于 RapidJSON 是仅需头文件的 JSON 库,我就按 Loitsch 的实现编写了一个 Grisu2 的头文件库,可以在 dtoa-benchmark,那里还比较了多个 dtoa() 实现的性能。因为 Grisu3 需要另一个更庞大的大数实现,而暂时 RapidJSON 不需要最优结果,所以就仅实现了一个性能更好及更简短的 Grisu2。
测试不同算法/实现下的性能(VC2013 64-bit),fpconv、grisu2、milo 都是 Grisu2 的实现,doubleconv 是 V8 的 Grisu3 实现。milo 对 sprintf 的加速比约是 9x。
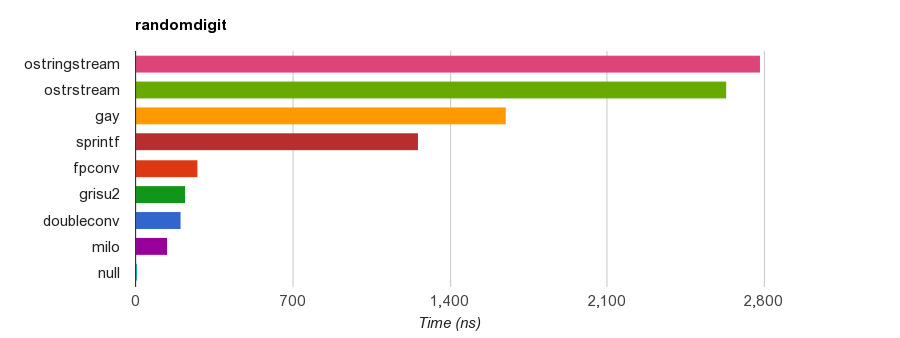
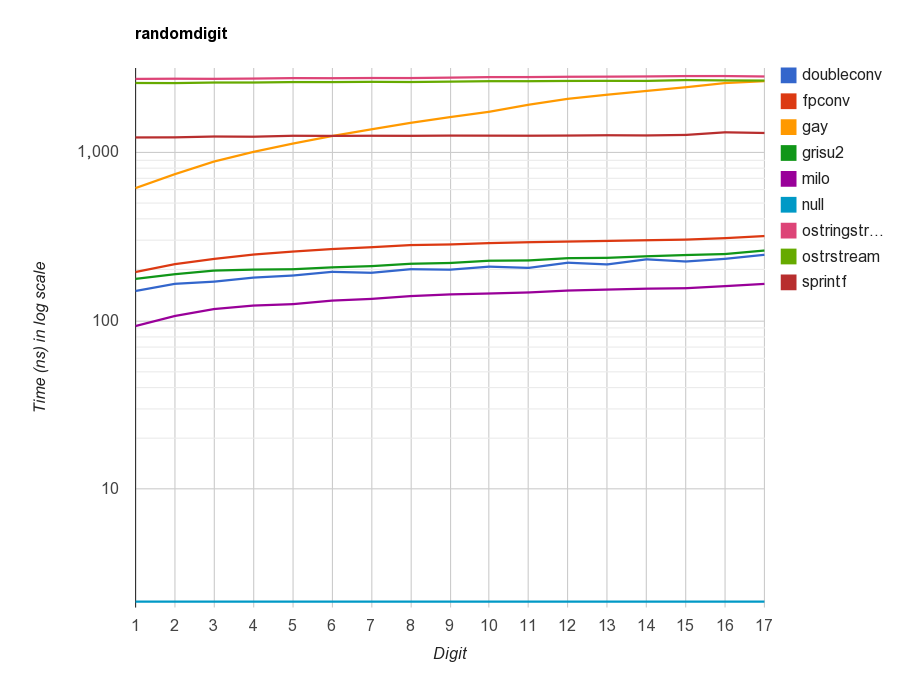
加入了经优化的 Grisu2 之后,RapidJSON 的 JSON 字符串化(stringify)性能远超其他 JSON 库。
整数除法优化
在原始论文[5] Grisu2 的digit_gen()函数(对应于 double-conversion 实现中的DigitGen())中,有一段代码是用于生成足够的十进位数位:
uint32_t p1 = /*...*/;
int kappa = 10;
uint32_t div = 1000000000;
while (kappa > 0) {
d = p1 / div; // 第一个除法
if (d || *len)
buffer[(*len)++] = static_cast<char>('0' + static_cast<char>(d));
p1 %= div;
kappa--;
div /= 10; // 第二个除法
// ...
}
在性能剖析时,我发现这段代码的32位无号整数除法成为一个瓶颈。
翻查一下资料[6],Intel Haswell 架构的 DIV 32位除法指令的延迟(latency)是 28 个周期,吞吐率是 10 个周期。作为比较,同一架构下 MUL 32位乘法指令的延迟只是 4 个周期,吞吐率只是半个周期。
在许多书籍(如[7])也会谈及,当除数为常数时,可以把除法变成乘以除数的倒数。现在的编译器都会自动做这个优化。事实上,在上面的代码里,第二个除法(div /= 10)中的除数(10)就是常数,编译器会自动把它优化成64位乘法及右移指令,例如 clang 在 x86-64 目标下:
mov esi, 0xcccccccd ; 3435973837
imul rsi, rax
shr rsi, 0x23 ; 35
注意到 $3435973837 \cdot 2^{-35} = 0.10000000000582076609134674072265625$,而这个精度足以应付任意32位无号整数除以10。
我们再分析原来的代码,会发现,其实除数 div 等于 $10^{\kappa - 1}$,我们可以使用常数除数令编译器进行上述的优化:
while (kappa > 0) {
uint32_t d = 0;
switch (kappa) {
case 9: d = p1 / 100000000; p1 %= 100000000; break;
case 8: d = p1 / 10000000; p1 %= 10000000; break;
case 7: d = p1 / 1000000; p1 %= 1000000; break;
case 6: d = p1 / 100000; p1 %= 100000; break;
case 5: d = p1 / 10000; p1 %= 10000; break;
case 4: d = p1 / 1000; p1 %= 1000; break;
case 3: d = p1 / 100; p1 %= 100; break;
case 2: d = p1 / 10; p1 %= 10; break;
case 1: d = p1; p1 = 0; break;
default:;
}
if (d || *len)
buffer[(*len)++] = static_cast<char>('0' + static_cast<char>(d));
kappa--;
// ...
}
这样的话,编译器就会把除法都变成乘法及右移。由于这个switch的 cases 是密集的,编译器也可使用 branch table 很好地优化它。不过缺点就是生成的机器码较原来多。
顺便一提,当整数模除运算(modulo operation)与除法成对出现时,而操作数相同,那么编译器会把模除运算生成一个乘法及减法:
这一节没有使用 intrinsic 或其他底层优化,只是手动把除法用另一个方式表达,就能达到有效的性能提升。
底层优化
然而,为了进一步提升性能,RapidJSON 也会尽量针对编译器/目标平台做一些优化。
例如,在 Grisu 算法中,需要实现一个自定义的浮点数类型(DiyFp),这个类型的乘法需要使用到一个 64 位整数乘法,并获得 128 位结果,然后进行数值修约(rounding)。然而,标准 C++ 中并没有获得 128 位乘法结果的方法,因此[5]提供了一个通用实现方法:
struct DiyFp {
DiyFp operator*(const DiyFp& rhs) const {
const uint64_t M32 = 0xFFFFFFFF;
const uint64_t a = f >> 32;
const uint64_t b = f & M32;
const uint64_t c = rhs.f >> 32;
const uint64_t d = rhs.f & M32;
const uint64_t ac = a * c;
const uint64_t bc = b * c;
const uint64_t ad = a * d;
const uint64_t bd = b * d;
uint64_t tmp = (bd >> 32) + (ad & M32) + (bc & M32);
tmp += 1U << 31; /// mult_round
return DiyFp(ac + (ad >> 32) + (bc >> 32) + (tmp >> 32), e + rhs.e + 64);
}
// ...
uint64_t f;
int e;
};
上面的通用实现可用于支持32位乘法并获得64位结果的编译器。然而,在许多 64 位 CPU 架构下,64位乘数是可以获得128位结果的。我们可以针对各编译器,使用 intrinsic 或扩展类型来实现这个函数:
DiyFp operator*(const DiyFp& rhs) const {
#if defined(_MSC_VER) && defined(_M_AMD64)
uint64_t h;
uint64_t l = _umul128(f, rhs.f, &h);
if (l & (uint64_t(1) << 63)) // rounding
h++;
return DiyFp(h, e + rhs.e + 64);
#elif (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 6)) && defined(__x86_64__)
__extension__ typedef unsigned __int128 uint128;
uint128 p = static_cast<uint128>(f) * static_cast<uint128>(rhs.f);
uint64_t h = static_cast<uint64_t>(p >> 64);
uint64_t l = static_cast<uint64_t>(p);
if (l & (uint64_t(1) << 63)) // rounding
h++;
return DiyFp(h, e + rhs.e + 64);
#else
// 通用实现
#endif
}
除此以外,这个 DiyFp 类型还要支持浮点数正规化(normalization)的操作,即把尾数(mantissa)的最高位变成 1(这个浮点数没有隐藏最高位):
DiyFp Normalize() const {
DiyFp res = *this;
while (!(res.f & (static_cast<uint64_t>(1) << 63))) {
res.f <<= 1;
res.e--;
}
return res;
}
许多 CPU 也支持 Find first set 指令,执行一个指令便能扫瞄到最高为1的位:
DiyFp Normalize() const {
#if defined(_MSC_VER) && defined(_M_AMD64)
unsigned long index;
_BitScanReverse64(&index, f);
return DiyFp(f << (63 - index), e - (63 - index));
#elif defined(__GNUC__) && __GNUC__ >= 4
int s = __builtin_clzll(f);
return DiyFp(f << s, e - s);
#else
// 通用实现
#endif
}
由于 gcc/clang 的内置函数能对不同目标平台生成最优的代码,使用起来更为方便。
结语
由于篇幅的关系,本文并没有仔细地解释 Grisu 的算法,而我也不认为能比原文[5]更浅白地介绍当中的原理。本文只是谈到两个优化方式,一个是利用常数除数令编译器能进行优化,而另一种优化则是由于 C++ 标准无法使用一些 CPU 提供的功能,而要采用编译器或平台相关的优化方法。
参考文献
[1] Coonen, Jerome T. “an Implementation Guide to a Proposed Standard for Floating-Point Arithmetic.” Computer 13.1 (1980): 68-79.
[2] Steele Jr, Guy L., and Jon L. White. “How to print floating-point numbers accurately.” ACM SIGPLAN Notices. Vol. 25. No. 6. ACM, 1990. http://kurtstephens.com/files/p372-steele.pdf
[3] Gay, David M. “Correctly rounded binary-decimal and decimal-binary conversions.” Numerical Analysis Manuscript 90-10 (1990). http://ampl.com/REFS/rounding.pdf
[4] Burger, Robert G., and R. Kent Dybvig. “Printing floating-point numbers quickly and accurately.” ACM SIGPLAN Notices. Vol. 31. No. 5. ACM, 1996. http://www.cs.indiana.edu/~dyb/pubs/FP-Printing-PLDI96.pdf
[5] Loitsch, Florian. “Printing floating-point numbers quickly and accurately with integers.” ACM Sigplan Notices 45.6 (2010): 233-243. http://www.cs.tufts.edu/~nr/cs257/archive/florian-loitsch/printf.pdf
[6] Granlund, Torbjörn. “Instruction latencies and throughput for AMD and Intel x86 processors, 2014.” https://gmplib.org/~tege/x86-timing.pdf
[7] Warren, Henry S. Hacker’s delight. Pearson Education, 2012.
Milo Yip
RAPIDJSON